热门问题
时间线
聊天
视角
支援向量機
用於監督統計學習的一套方法 来自维基百科,自由的百科全书

Remove ads
在機器學習中,支援向量機 (中國大陸稱支持向量机,英語:support vector machine,常簡稱為SVM,又名支援向量網絡[1])是在分類與迴歸分析中分析數據的監督式學習模型與相關的學習演算法。給定一組訓練實例,每個訓練實例被標記為屬於兩個類別中的一個或另一個,SVM訓練演算法建立一個將新的實例分配給兩個類別之一的模型,使其成為非概率二元線性分類器。SVM模型是將實例表示為空間中的點,這樣對映就使得單獨類別的實例被儘可能寬的明顯的間隔分開。然後,將新的實例對映到同一空間,並基於它們落在間隔的哪一側來預測所屬類別。
除了進行線性分類之外,SVM還可以使用所謂的核技巧有效地進行非線性分類,將其輸入隱式對映到高維特徵空間中。
當數據未被標記時,不能進行監督式學習,需要用非監督式學習,它會嘗試找出數據到簇的自然聚類,並將新數據對映到這些已形成的簇。將支援向量機改進的聚類演算法被稱為支援向量聚類[2],當數據未被標記或者僅一些數據被標記時,支援向量聚類經常在工業應用中用作分類步驟的預處理。
Remove ads
動機
.svg)
將數據進行分類是機器學習中的一項常見任務。 假設某些給定的數據點各自屬於兩個類之一,而目標是確定新數據點將在哪個類中。對於支援向量機來說,數據點被視為 維向量,而我們想知道是否可以用 維超平面來分開這些點。這就是所謂的線性分類器。可能有許多超平面可以把數據分類。最佳超平面的一個合理選擇是以最大間隔把兩個類分開的超平面。因此,我們要選擇能夠讓到每邊最近的數據點的距離最大化的超平面。如果存在這樣的超平面,則稱為最大間隔超平面,而其定義的線性分類器被稱為最大間隔分類器,或者叫做最佳穩定性感知器。[來源請求]


Remove ads
定義
更正式地來說,支援向量機在高維或無限維空間中構造超平面或超平面集合,其可以用於分類、回歸或其他任務。直觀來說,分類邊界距離最近的訓練資料點越遠越好,因為這樣可以縮小分類器的泛化誤差。

儘管原始問題可能是在有限維空間中陳述的,但用於區分的集合在該空間中往往線性不可分。為此,有人提出將原有限維空間對映到維數高得多的空間中,在該空間中進行分離可能會更容易。為了保持計算負荷合理,人們選擇適合該問題的核函數 來定義SVM方案使用的對映,以確保用原始空間中的變量可以很容易計算點積。[3] 高維空間中的超平面定義為與該空間中的某向量的點積是常數的點的集合。定義超平面的向量可以選擇在數據集中出現的特徵向量 的圖像的參數 的線性組合。通過選擇超平面,被對映到超平面上的特徵空間中的點集 由以下關係定義: 注意,如果隨着 逐漸遠離 , 變小,則求和中的每一項都是在衡量測試點 與對應的數據基點 的接近程度。這樣,上述內核的總和可以用于衡量每個測試點相對於待分離的集合中的數據點的相對接近度。






Remove ads
應用
- 用於文字和超文字的分類,在歸納和直推方法中都可以顯著減少所需要的有類標的樣本數。
- 用於圖像分類。實驗結果顯示:在經過三到四輪相關反饋之後,比起傳統的查詢最佳化方案,支援向量機能夠取得明顯更高的搜尋準確度。這同樣也適用於圖像分割系統,比如使用Vapnik所建議的使用特權方法的修改版本SVM的那些圖像分割系統。[4][5]
- 用於手寫字型辨識。
- 用於醫學中分類蛋白質,超過90%的化合物能夠被正確分類。基於支援向量機權重的置換測試已被建議作為一種機制,用於解釋的支援向量機模型。[6][7] 支援向量機權重也被用來解釋過去的SVM模型。[8] 為辨識模型用於進行預測的特徵而對支援向量機模型做出事後解釋是在生物科學中具有特殊意義的相對較新的研究領域。
歷史
原始SVM演算法是由蘇聯數學家弗拉基米爾·瓦普尼克和亞歷克塞·澤范蘭傑斯於1963年發明的。1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎貝爾·M·蓋昂(Isabelle M. Guyon)和瓦普尼克提出了一種通過將核技巧應用於最大間隔超平面來建立非線性分類器的方法。[9] 當前標準的前身(軟間隔)由科琳娜·科特斯和瓦普尼克於1993年提出,並於1995年發表。[1]
線性SVM
我們考慮以下形式的 點測試集:


其中 是 1 或者 −1,表明點 所屬的類。 中每個都是一個 維實向量。我們要求將 的點集 與 的點集分開的 「最大間隔超平面」,使得超平面與最近的點 之間的距離最大化。




任何超平面都可以寫作滿足下面方程的點集

-
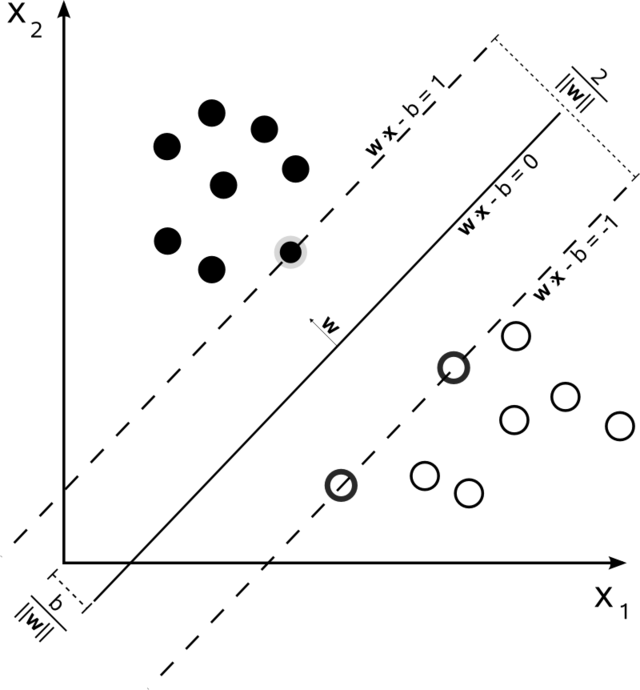
設樣本屬於兩個類,用該樣本訓練SVM得到的最大間隔超平面。在邊緣上的樣本點稱為支援向量。


其中 (不必是歸一化的)是該法向量。參數 決定從原點沿法向量 到超平面的偏移量。


Remove ads
如果這些訓練數據是線性可分的,可以選擇分離兩類數據的兩個平行超平面,使得它們之間的距離儘可能大。在這兩個超平面範圍內的區域稱為「間隔」,最大間隔超平面是位於它們正中間的超平面。這些超平面可以由方程:

或是

來表示。通過幾何不難得到這兩個超平面之間的距離是 ,因此要使兩平面間的距離最大,我們需要最小化 。同時為了使得樣本數據點都在超平面的間隔區以外,我們需要保證對於所有的 滿足其中的一個條件:



- 若

或是
- 若


這些約束表明每個數據點都必須位於間隔的正確一側。
這兩個式子可以寫作:

可以用這個式子一起來得到最佳化問題:
「在 條件下,最小化 ,對於 "


這個問題的解 與 決定了我們的分類器 。


此幾何描述的一個顯而易見卻重要的結果是,最大間隔超平面完全是由最靠近它的那些 確定的。這些 叫做支援向量。
Remove ads
為了將SVM擴充到數據線性不可分的情況,我們引入鉸鏈損失函數,

當約束條件 (1) 滿足時(也就是如果 位於邊距的正確一側)此函數為零。對於間隔的錯誤一側的數據,該函數的值與距間隔的距離成正比。 然後我們希望最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\vec {w}}\cdot {\vec {x_{i}}}-b)\right)\right]+\lambda \lVert {\vec {w}}\rVert ^{2},}](http://wikimedia.org/api/rest_v1/media/math/render/svg/edfd21a4d3cb290e872f527487f0df3d29a90ce7)
其中參數 用來權衡增加間隔大小與確保 位於間隔的正確一側之間的關係。因此,對於足夠小的 值,如果輸入數據是可以線性分類的,則軟間隔SVM與硬間隔SVM將表現相同,但即使不可線性分類,仍能學習出可行的分類規則。

Remove ads
非線性分類
弗拉基米爾·瓦普尼克在1963年提出的原始最大間隔超平面演算法構造了一個線性分類器。而1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎貝爾·M·蓋昂(Isabelle M. Guyon)和瓦普尼克提出了一種通過將核技巧(最初由Aizerman et al.[10]提出)應用於最大邊界超平面來建立非線性分類器的方法。[11] 所得到的演算法形式上類似,除了把點積換成了非線性核函數。這就允許演算法在變換後的特徵空間中擬合最大間隔超平面。該變換可以是非線性的,而變換空間是高維的;雖然分類器是變換後的特徵空間中的超平面,但它在原始輸入空間中可以是非線性的。
值得注意的是,更高維的特徵空間增加了支援向量機的泛化誤差,但給定足夠多的樣本,演算法仍能表現良好。[12]
常見的核函數包括:








由等式 ,核函數與變換 有關。變換空間中也有 w 值,。與 w 的點積也要用核技巧來計算,即 。




Remove ads
計算SVM分類器
計算(軟間隔)SVM分類器等同於使下面表達式最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.\qquad (2)}](http://wikimedia.org/api/rest_v1/media/math/render/svg/80a65393b87bcf565f42cdc02cf9caafe49ec14a)
如上所述,由於我們關注的是軟間隔分類器, 選擇足夠小的值就能得到線性可分類輸入數據的硬間隔分類器。下面會詳細介紹將(2)簡化為二次規劃問題的經典方法。之後會討論一些最近才出現的方法,如次梯度下降法和坐標下降法。
最小化(2)可以用下面的方式覆寫為目標函數可微的約束最佳化問題。
對所有 我們引入變量 。注意到 是滿足 的最小非負數。




因此,我們可以將最佳化問題敍述如下


這就叫做原型問題。
Remove ads
通過求解上述問題的拉格朗日對偶,得到簡化的問題


這就叫做對偶問題。由於對偶最小化問題是受線性約束的 的二次函數,所以它可以通過二次規劃演算法高效地解出。 這裏,變量 定義為滿足

.

此外,當 恰好在間隔的正確一側時 ,且當 位於間隔的邊界時 。因此, 可以寫為支援向量的線性組合。 可以通過在間隔的邊界上找到一個 並求解



得到偏移量 。(注意由於 因而 。)


Remove ads
总结
视角
假設我們要學習與變換後數據點 的線性分類規則對應的非線性分類規則。此外,我們有一個滿足 的核函數 。



我們知道變換空間中的分類向量 滿足

其中 可以通過求解最佳化問題

得到。與前面一樣,可以使用二次規劃來求解係數 。同樣,我們可以找到讓 的索引 ,使得 位於變換空間中間隔的邊界上,然後求解
![{\displaystyle {\begin{aligned}b={\vec {w}}\cdot \varphi ({\vec {x}}_{i})-y_{i}&=\left[\sum _{k=1}^{n}c_{k}y_{k}\varphi ({\vec {x}}_{k})\cdot \varphi ({\vec {x}}_{i})\right]-y_{i}\\&=\left[\sum _{k=1}^{n}c_{k}y_{k}k({\vec {x}}_{k},{\vec {x}}_{i})\right]-y_{i}.\end{aligned}}}](http://wikimedia.org/api/rest_v1/media/math/render/svg/beb6300a0eb50faa0574ba613a7e960b612aaf91)
最後,可以通過計算下式來分類新點
![{\displaystyle {\vec {z}}\mapsto \operatorname {sgn}({\vec {w}}\cdot \varphi ({\vec {z}})+b)=\operatorname {sgn} \left(\left[\sum _{i=1}^{n}c_{i}y_{i}k({\vec {x}}_{i},{\vec {z}})\right]+b\right).}](http://wikimedia.org/api/rest_v1/media/math/render/svg/122836b654fa6e79b1e5f4250eeb07695c217198)
用於找到SVM分類器的最近的演算法包括次梯度下降和坐標下降。當處理大的稀疏數據集時,這兩種技術已經被證明有着顯著的優點——當存在許多訓練實例時次梯度法是特別有效的,並且當特徵空間的維度高時,坐標下降特別有效。
SVM的次梯度下降演算法直接用表達式
![{\displaystyle f({\vec {w}},b)=\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.}](http://wikimedia.org/api/rest_v1/media/math/render/svg/1025985789e0160e43d58d13fc27bda0f5ab9296)
注意 是 與 的凸函數。因此,可以採用傳統的梯度下降(或SGD)方法,其中不是在函數梯度的方向上前進,而是在從函數的次梯度中選出的向量的方向上前進。該方法的優點在於,對於某些實現,迭代次數不隨着數據點的數量 而增加或減少。[13]

SVM的坐標下降演算法基於對偶問題
對所有 進行迭代,使係數 的方向與 一致。然後,將所得的係數向量 投影到滿足給定約束的最接近的係數向量。(通常使用歐氏距離。)然後重複該過程,直到獲得接近最佳的係數向量。所得的演算法在實踐中執行非常快,儘管已經證明的效能保證很少。[14]


性質
SVM屬於廣義線性分類器的一族,並且可以解釋為感知器的延伸。它們也可以被認為是吉洪諾夫正則化的特例。它們有一個特別的性質,就是可以同時最小化經驗誤差和最大化幾何邊緣區; 因此它們也被稱為最大間隔分類器。
Meyer、Leisch和Hornik對SVM與其他分類器進行了比較。[15]
SVM的有效性取決於核函數、核參數和軟間隔參數 C 的選擇。 通常會選只有一個參數 的高斯核。C 和 的最佳組合通常通過在 C 和 為指數增長序列下網格搜尋來選取,例如 ; 。通常情況下,使用交叉驗證來檢查參數選擇的每一個組合,並選擇具有最佳交叉驗證精度的參數。或者,最近在貝葉斯最佳化中的工作可以用於選擇C和γ,通常需要評估比網格搜尋少得多的參陣列合。或者,貝葉斯最佳化的最近進展可以用於選擇 C 和 ,通常需要計算的參陣列合比網格搜尋少得多。然後,使用所選擇的參數在整個訓練集上訓練用於測試和分類新數據的最終模型。[16]



SVM的潛在缺點包括以下方面:
- 需要對輸入數據進行完全標記
- 未校準類別成員概率
- SVM僅直接適用於兩類任務。因此,必須應用將多類任務減少到幾個二元問題的演算法;請參閱多類SVM一節。
- 解出的模型的參數很難理解。
延伸
- 支援向量聚類:支援向量聚類是一種建立在核函數上的類似方法,同適用於非監督學習和數據挖掘。它被認為是數據科學中的一種基本方法。
- 轉導支援向量機
- 多元分類支援向量機:SVM演算法最初是為二值分類問題設計的,實現多分類的主要方法是將一個多分類問題轉化為多個二分類問題。常見方法包括「一對多法」和「一對一法」,一對多法是將某個類別的樣本歸為一類,其他剩餘的樣本歸為另一類,這樣k個類別的樣本就構造出了k個二分類SVM;一對一法則是在任意兩類樣本之間設計一個SVM。
- 支援向量回歸
- 結構化支援向量機:支援向量機可以被推廣為結構化的支援向量機,推廣後標籤空間是結構化的並且可能具有無限的大小。
實現
最大間隔超平面的參數是通過求解最佳化得到的。有幾種專門的演算法可用於快速解決由SVM產生的QP問題,它們主要依靠啟發式演算法將問題分解成更小、更易於處理的子問題。
另一種方法是使用內點法,其使用類似牛頓法的迭代找到卡羅需-庫恩-塔克條件下原型和對偶型的解。[17] 這種方法不是去解決一系列分解問題,而是直接完全解決該問題。為了避免求解核矩陣很大的線性系統,在核技巧中經常使用矩陣的低秩近似。
另一個常見的方法是普萊特的序列最小最佳化演算法(SMO),它把問題分成了若干個可以解析求解的二維子問題,這樣就可以避免使用數值最佳化演算法和矩陣儲存。[18]
線性支援向量機的特殊情況可以通過用於最佳化其類似問題邏輯斯諦迴歸的同類演算法更高效求解;這類演算法包括次梯度下降法(如PEGASOS[19])和坐標下降法(如LIBLINEAR[20])。LIBLINEAR有一些引人注目的訓練時間上的特性。每次收斂迭代花費在讀取訓練數據上的時間是線性的,而且這些迭代還具有Q-線性收斂特性,使得演算法非常快。
一般的核SVM也可以用次梯度下降法(P-packSVM[21])更快求解,在允許並列化時求解速度尤其快。
許多機器學習工具包都可以使用核SVM,有LIBSVM、MATLAB、SAS[22]、SVMlight、kernlab[23]、scikit-learn、Shogun、Weka、Shark[24]、JKernelMachines[25]、OpenCV等。
參見
- 核方法
- 費希爾核
- 多項式核函數
- 預測分析
- 相關向量機,函數形式與SVM相同的概率稀疏核模型
- 序列最小最佳化演算法
- 空間對映
參考文獻
外部連結
Wikiwand - on
Seamless Wikipedia browsing. On steroids.
Remove ads