Velvet是处理从头测序(de novo)基因组组装及短读长序列比对的一个算法包。这是使用德布鲁因图通过消除错误和化简重复区域而来进行基因组序列组装。[2] Geneious、MacVector、BioNumerics等商业软件包的内部也实现了Velvet。
简介
第二代定序仪 (NGS)的开发增加了很短读长测序的成本效率。使用德布鲁因图来比对的方法符合实际需求,但进一步的开发需要解决错误和重复的问题。[3] 这促使欧洲生物信息研究所的Daniel Zerbino和尤安·伯尼在英国开发了Velvet。[4]
Velvet可以通过化简和压缩来快速操纵德布鲁因图,而不丢失图的信息,把不相交的路径聚成单个节点。它通过首先使用合并序列的错误校正算法消除了错误消除错误,并解决重读。
将read和read pair组合让Velvet解决小的重复并产生合理长度的重叠序列。Velvet的应用对双端(测序的)原核生物数据和哺乳动物区域可以产生N50长度 50 kb 的重叠序列。
算法
正如前文所述,Velvet使用德布鲁因图(de Bruijn图)来组装短的读长序列。更具体地讲,Velvet将从读长序列得到的每个不同的k-mer表示为图上的一个唯一的节点。如果两个节点的k-mer有 k-1 个碱基重叠,则两个节点是相连的。换句话说,只有在节点A的k-mer的后 k-1 个碱基与节点B的k-mer的前 k-1 个碱基相同时,节点A和B之间才会有一条弧连接在一起。下图显示了Velvet生成的一个德布鲁因图:

相同的过程也同时作用于所有k-mer的反向互补序列用来考虑相对的链上读长序列重叠的情况。可以对图进行一些优化,包括化简以及消除错误。
节省内存的一个简单方法就是把不影响该图生成的路径下将融合节点,即当节点A只有一个指向节点B的出弧,而节点B又只有一个入弧时,这两个节点可以融合。将他们和他们所有的信息融合之后,就可以用一个节点表示两个了。下图说明了一开始的例子的简化中的此过程。

图中的错误有可能是由于测序过程引起的,或者也有可能是生物样本包含一些错误(例如多态性)。 Velvet可以识别三种错误:尖端、气泡;还有错误的连接。
如果一个节点在它其中一端是未连接的,该节点储存的信息量小于2k,并且相对于其他路径的重复度(建立这个图时访问该弧的次数)较低则将其视为尖端。一旦这些错误被清除了,这个图就会再一次地简化。

当两条路径在同一个节点开始和结束时产生气泡。气泡通常是由错误或生物变异引起的。使用旅游巴士算法(与戴克斯特拉算法类似,是一种检测最佳路径并决定哪些应该被删除的广度优先搜索)可以去除这些错误。一个简单的例子如图4所示。

接在图1和2的后面,图5也显示了这个过程。
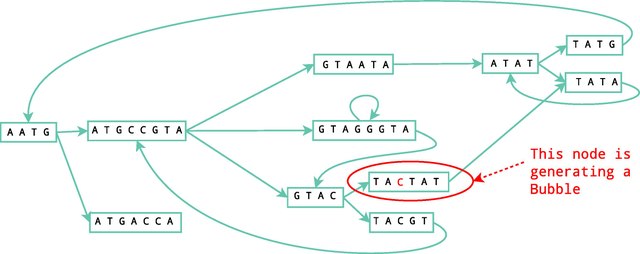
错误连接是图中不能生成正确路径或不能建立任何可识别结构。Velvet应用必须用户定义的简单的覆盖率截止的旅游巴士算法清除了这些错误。
Velvet命令
Velvet提供工下列函数:
- velveth
- 此命令帮助velvetg建立数据集(将读长序列散列化),并包含每个序列含义的信息。
- velvetg
- 此命令从velveth得到的k-mer建立de Bruijn图,并对整个图运行化简和错误更正。然后提取重叠片段。
在运行完velvetg之后,会生成一些文件。最重要的是,重叠序列(contig)文件中包含长度超过2k的重叠序列,其中k是velveth中用到的字长。
开发目的
目前的DNA测序技术,包括NGS,都限制在基因比任何读长都长。通常NGS处理小于400 bp的短读长片段,每个读长的成本也比之前的第一代机器少很多。在高度并行化的操作下操作简单,产量也高。[3]
但是由于短读长包含的信息少,为了重叠片段可以检测,需要更高的组装读长覆盖率。这反过来增加了测序的复杂度,并显著增加了计算的要求。更多的读长序列增大了重叠图,使之更长、计算更困难了。由于重叠部分的减少,读长序列之间的连接会更加不明显,产生更高的误差可能性。
为了克服这些问题,开发出了高效的动态测序程序,不仅成本效率高,还能解决错误和重复。开发Velvet算法就是为了解决此问题,并在相对较短的计算时间内,使用相比其他拼接软件更少的内存,进行短读长从头测序序列比对。[6]
图形界面
Velvet的一个主要缺点是使用命令行界面,但用户(尤其是初学者)在对他们的数据实现的时候会遇到困难。[7] 2012年开发出了图形界面来克服这个问题,并简化Velvet的运行。
参见
- SPAdes (软件)
参考文献
Wikiwand - on
Seamless Wikipedia browsing. On steroids.