在机器学习与数据挖掘领域,轮廓 指的是一种反映数据聚类 结果一致性的方法,可以用于评估聚类后簇与簇之间的离散程度。[ 1]
该图显示了Orange数据挖掘套件渲染的动物园数据集中的三种动物的轮廓。 在图底部的轮廓值反映了该数据集中海豚和鼠海豚是离群值(outlier) 假设某一数据集使用如k-means 等聚类方法分成了
k
{\displaystyle k}
对于某一属于簇
C
i
{\displaystyle C_{i}}
i
{\displaystyle i}
i
∈
C
i
{\displaystyle i\in C_{i}}
d
(
i
,
j
)
{\displaystyle d(i,j)}
i
{\displaystyle i}
j
{\displaystyle j}
i
{\displaystyle i}
d
(
i
,
i
)
{\displaystyle d(i,i)}
|
C
i
|
−
1
{\displaystyle |C_{i}|-1}
a
(
i
)
=
1
|
C
i
|
−
1
∑
j
∈
C
i
,
i
≠
j
d
(
i
,
j
)
{\displaystyle a(i)={\frac {1}{|C_{i}|-1}}\sum _{j\in C_{i},i\neq j}d(i,j)}
上述公式结果记为
a
(
i
)
{\displaystyle a(i)}
i
{\displaystyle i}
然后,我们定义样本与某簇
C
k
{\displaystyle C_{k}}
i
{\displaystyle i}
i
{\displaystyle i}
C
k
{\displaystyle C_{k}}
C
k
≠
C
i
{\displaystyle C_{k}\neq C_{i}}
i
∈
C
i
{\displaystyle i\in C_{i}}
i
{\displaystyle i}
b
(
i
)
{\displaystyle b(i)}
C
k
{\displaystyle C_{k}}
i
{\displaystyle i}
b
(
i
)
=
min
k
≠
i
1
|
C
k
|
∑
j
∈
C
k
d
(
i
,
j
)
{\displaystyle b(i)=\min _{k\neq i}{\frac {1}{|C_{k}|}}\sum _{j\in C_{k}}d(i,j)}
结合上述内容,我们定义
i
{\displaystyle i}
s
(
i
)
=
b
(
i
)
−
a
(
i
)
max
{
a
(
i
)
,
b
(
i
)
}
{\displaystyle s(i)={\frac {b(i)-a(i)}{\max\{a(i),b(i)\}}}}
等效为:
s
(
i
)
=
{
1
−
a
(
i
)
/
b
(
i
)
,
if
a
(
i
)
<
b
(
i
)
0
,
if
a
(
i
)
=
b
(
i
)
b
(
i
)
/
a
(
i
)
−
1
,
if
a
(
i
)
>
b
(
i
)
{\displaystyle s(i)={\begin{cases}1-a(i)/b(i),&{\mbox{if }}a(i)<b(i)\\0,&{\mbox{if }}a(i)=b(i)\\b(i)/a(i)-1,&{\mbox{if }}a(i)>b(i)\\\end{cases}}}
对于上述定义,显然
−
1
≤
s
(
i
)
≤
1.
{\displaystyle -1\leq s(i)\leq 1.}
为了防止簇数量暴增,对于仅有一个样本的簇(
|
C
i
|
=
1
{\displaystyle |C_{i}|=1}
s
(
i
)
=
0
{\displaystyle s(i)=0}
a
(
i
)
{\displaystyle a(i)}
i
{\displaystyle i}
a
(
i
)
{\displaystyle a(i)}
b
(
i
)
{\displaystyle b(i)}
i
{\displaystyle i}
s
(
i
)
{\displaystyle s(i)}
a
(
i
)
≪
b
(
i
)
{\displaystyle a(i)\ll b(i)}
[ 2]
考夫曼(Kaufman)等人定义了轮廓系数(silhouette coefficient )的概念——在某个数据集的有限种聚类方法中,平均
s
(
i
)
{\displaystyle s(i)}
[ 3]
S
C
=
max
k
s
~
(
k
)
{\displaystyle SC=\max _{k}{\tilde {s}}\left(k\right)}
上式中
s
~
(
k
)
{\displaystyle {\tilde {s}}\left(k\right)}
k
{\displaystyle k}
s
(
i
)
{\displaystyle s(i)}
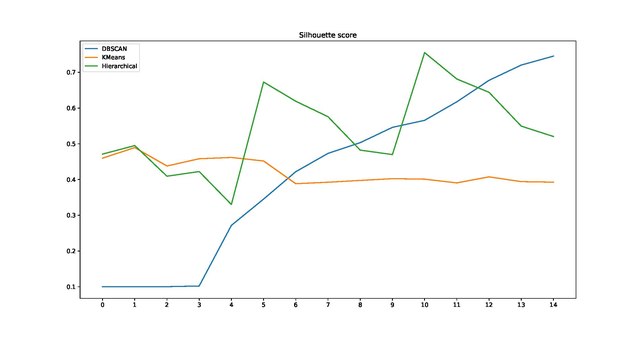
轮廓系数一般不能用于横向评价多种聚类方法。凸簇(如经由DBSCAN方法得出的簇)的轮廓系数一般高于其他类型的簇。
途中蓝色线条是DBSCAN的轮廓系数,随着参数变化其SC迅速增大。然而实际聚类结果很差。
Davies–Bouldin指数
k-medoids
如何确定数据集中有多少簇