支持向量机
用於監督統計學習的一套方法 来自维基百科,自由的百科全书

在机器学习中,支持向量机 (台湾称支援向量機,英语:support vector machine,常简称为SVM,又名支援向量网络[1])是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法建立一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。
当数据未被标记时,不能进行监督式学习,需要用非监督式学习,它会尝试找出数据到簇的自然聚类,并将新数据映射到这些已形成的簇。将支援向量机改进的聚类算法被称为支援向量聚类[2],当数据未被标记或者仅一些数据被标记时,支援向量聚类经常在工业应用中用作分类步骤的预处理。
动机
.svg)
将数据进行分类是机器学习中的一项常见任务。 假设某些给定的数据点各自属于两个类之一,而目标是确定新数据点将在哪个类中。对于支持向量机来说,数据点被视为 维向量,而我们想知道是否可以用 维超平面来分开这些点。这就是所谓的线性分类器。可能有许多超平面可以把数据分类。最佳超平面的一个合理选择是以最大间隔把两个类分开的超平面。因此,我们要选择能够让到每边最近的数据点的距离最大化的超平面。如果存在这样的超平面,则称为最大间隔超平面,而其定义的线性分类器被称为最大间隔分类器,或者叫做最佳稳定性感知器。[来源请求]


定义
更正式地来说,支持向量机在高维或无限维空间中构造超平面或超平面集合,其可以用于分类、回归或其他任务。直观来说,分类边界距离最近的训练资料点越远越好,因为这样可以缩小分类器的泛化误差。

尽管原始问题可能是在有限维空间中陈述的,但用于区分的集合在该空间中往往线性不可分。为此,有人提出将原有限维空间映射到维数高得多的空间中,在该空间中进行分离可能会更容易。为了保持计算负荷合理,人们选择适合该问题的核函数 来定义SVM方案使用的映射,以确保用原始空间中的变量可以很容易计算点积。[3] 高维空间中的超平面定义为与该空间中的某向量的点积是常数的点的集合。定义超平面的向量可以选择在数据集中出现的特征向量 的图像的参数 的线性组合。通过选择超平面,被映射到超平面上的特征空间中的点集 由以下关系定义: 注意,如果随着 逐渐远离 , 变小,则求和中的每一项都是在衡量测试点 与对应的数据基点 的接近程度。这样,上述内核的总和可以用于衡量每个测试点相对于待分离的集合中的数据点的相对接近度。






应用
- 用于文本和超文本的分类,在归纳和直推方法中都可以显著减少所需要的有类标的样本数。
- 用于图像分类。实验结果显示:在经过三到四轮相关反馈之后,比起传统的查询优化方案,支持向量机能够取得明显更高的搜索准确度。这同样也适用于图像分割系统,比如使用Vapnik所建议的使用特权方法的修改版本SVM的那些图像分割系统。[4][5]
- 用于手写字体识别。
- 用于医学中分类蛋白质,超过90%的化合物能够被正确分类。基于支持向量机权重的置换测试已被建议作为一种机制,用于解释的支持向量机模型。[6][7] 支持向量机权重也被用来解释过去的SVM模型。[8] 为识别模型用于进行预测的特征而对支持向量机模型做出事后解释是在生物科学中具有特殊意义的相对较新的研究领域。
历史
原始SVM算法是由苏联数学家弗拉基米尔·瓦普尼克和亚历克塞·泽范兰杰斯于1963年发明的。1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎贝尔·M·盖昂(Isabelle M. Guyon)和瓦普尼克提出了一种通过将核技巧应用于最大间隔超平面来创建非线性分类器的方法。[9] 当前标准的前身(软间隔)由科琳娜·科特斯和瓦普尼克于1993年提出,并于1995年发表。[1]
线性SVM
我们考虑以下形式的 点测试集:


其中 是 1 或者 −1,表明点 所属的类。 中每个都是一个 维实向量。我们要求将 的点集 与 的点集分开的 “最大间隔超平面”,使得超平面与最近的点 之间的距离最大化。




任何超平面都可以写作满足下面方程的点集

-
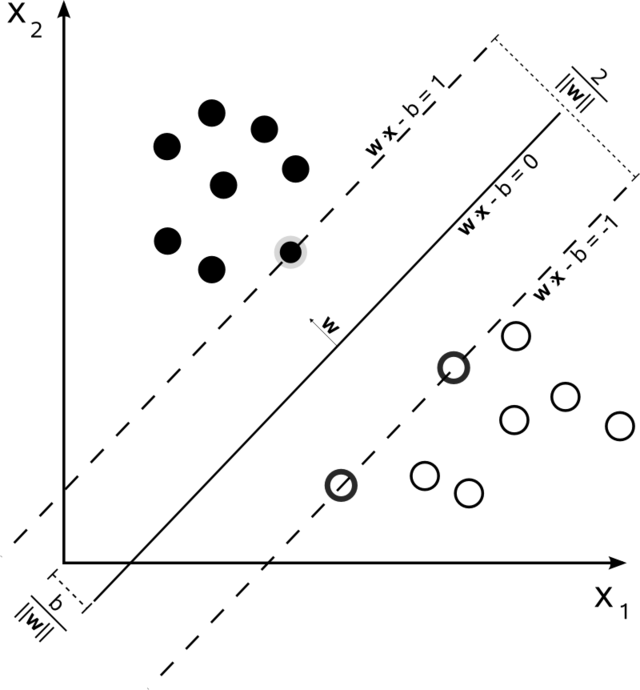
设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在边缘上的样本点称为支持向量。


其中 (不必是归一化的)是该法向量。参数 决定从原点沿法向量 到超平面的偏移量。


如果这些训练数据是线性可分的,可以选择分离两类数据的两个平行超平面,使得它们之间的距离尽可能大。在这两个超平面范围内的区域称为“间隔”,最大间隔超平面是位于它们正中间的超平面。这些超平面可以由方程:

或是

来表示。通过几何不难得到这两个超平面之间的距离是 ,因此要使两平面间的距离最大,我们需要最小化 。同时为了使得样本数据点都在超平面的间隔区以外,我们需要保证对于所有的 满足其中的一个条件:



- 若

或是
- 若


这些约束表明每个数据点都必须位于间隔的正确一侧。
这两个式子可以写作:

可以用这个式子一起来得到优化问题:
“在 条件下,最小化 ,对于 "


这个问题的解 与 决定了我们的分类器 。


此几何描述的一个显而易见却重要的结果是,最大间隔超平面完全是由最靠近它的那些 确定的。这些 叫做支持向量。
为了将SVM扩展到数据线性不可分的情况,我们引入铰链损失函数,

当约束条件 (1) 满足时(也就是如果 位于边距的正确一侧)此函数为零。对于间隔的错误一侧的数据,该函数的值与距间隔的距离成正比。 然后我们希望最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\vec {w}}\cdot {\vec {x_{i}}}-b)\right)\right]+\lambda \lVert {\vec {w}}\rVert ^{2},}](http://wikimedia.org/api/rest_v1/media/math/render/svg/edfd21a4d3cb290e872f527487f0df3d29a90ce7)
其中参数 用来权衡增加间隔大小与确保 位于间隔的正确一侧之间的关系。因此,对于足够小的 值,如果输入数据是可以线性分类的,则软间隔SVM与硬间隔SVM将表现相同,但即使不可线性分类,仍能学习出可行的分类规则。

非线性分类
弗拉基米尔·瓦普尼克在1963年提出的原始最大间隔超平面算法构造了一个线性分类器。而1992年,伯恩哈德·E·博瑟(Bernhard E. Boser)、伊莎贝尔·M·盖昂(Isabelle M. Guyon)和瓦普尼克提出了一种通过将核技巧(最初由Aizerman et al.[10]提出)应用于最大边界超平面来创建非线性分类器的方法。[11] 所得到的算法形式上类似,除了把点积换成了非线性核函数。这就允许算法在变换后的特征空间中拟合最大间隔超平面。该变换可以是非线性的,而变换空间是高维的;虽然分类器是变换后的特征空间中的超平面,但它在原始输入空间中可以是非线性的。
值得注意的是,更高维的特征空间增加了支持向量机的泛化误差,但给定足够多的样本,算法仍能表现良好。[12]
常见的核函数包括:








由等式 ,核函数与变换 有关。变换空间中也有 w 值,。与 w 的点积也要用核技巧来计算,即 。




计算SVM分类器
计算(软间隔)SVM分类器等同于使下面表达式最小化
![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.\qquad (2)}](http://wikimedia.org/api/rest_v1/media/math/render/svg/80a65393b87bcf565f42cdc02cf9caafe49ec14a)
如上所述,由于我们关注的是软间隔分类器, 选择足够小的值就能得到线性可分类输入数据的硬间隔分类器。下面会详细介绍将(2)简化为二次规划问题的经典方法。之后会讨论一些最近才出现的方法,如次梯度下降法和坐标下降法。
最小化(2)可以用下面的方式改写为目标函数可微的约束优化问题。
对所有 我们引入变量 。注意到 是满足 的最小非负数。




因此,我们可以将优化问题叙述如下


这就叫做原型问题。
通过求解上述问题的拉格朗日对偶,得到简化的问题


这就叫做对偶问题。由于对偶最小化问题是受线性约束的 的二次函数,所以它可以通过二次规划算法高效地解出。 这里,变量 定义为满足

.

此外,当 恰好在间隔的正确一侧时 ,且当 位于间隔的边界时 。因此, 可以写为支持向量的线性组合。 可以通过在间隔的边界上找到一个 并求解



得到偏移量 。(注意由于 因而 。)


总结
视角
假设我们要学习与变换后数据点 的线性分类规则对应的非线性分类规则。此外,我们有一个满足 的核函数 。



我们知道变换空间中的分类向量 满足

其中 可以通过求解优化问题

得到。与前面一样,可以使用二次规划来求解系数 。同样,我们可以找到让 的索引 ,使得 位于变换空间中间隔的边界上,然后求解
![{\displaystyle {\begin{aligned}b={\vec {w}}\cdot \varphi ({\vec {x}}_{i})-y_{i}&=\left[\sum _{k=1}^{n}c_{k}y_{k}\varphi ({\vec {x}}_{k})\cdot \varphi ({\vec {x}}_{i})\right]-y_{i}\\&=\left[\sum _{k=1}^{n}c_{k}y_{k}k({\vec {x}}_{k},{\vec {x}}_{i})\right]-y_{i}.\end{aligned}}}](http://wikimedia.org/api/rest_v1/media/math/render/svg/beb6300a0eb50faa0574ba613a7e960b612aaf91)
最后,可以通过计算下式来分类新点
![{\displaystyle {\vec {z}}\mapsto \operatorname {sgn}({\vec {w}}\cdot \varphi ({\vec {z}})+b)=\operatorname {sgn} \left(\left[\sum _{i=1}^{n}c_{i}y_{i}k({\vec {x}}_{i},{\vec {z}})\right]+b\right).}](http://wikimedia.org/api/rest_v1/media/math/render/svg/122836b654fa6e79b1e5f4250eeb07695c217198)
用于找到SVM分类器的最近的算法包括次梯度下降和坐标下降。当处理大的稀疏数据集时,这两种技术已经被证明有着显著的优点——当存在许多训练实例时次梯度法是特别有效的,并且当特征空间的维度高时,坐标下降特别有效。
SVM的次梯度下降算法直接用表达式
![{\displaystyle f({\vec {w}},b)=\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(w\cdot x_{i}+b)\right)\right]+\lambda \lVert w\rVert ^{2}.}](http://wikimedia.org/api/rest_v1/media/math/render/svg/1025985789e0160e43d58d13fc27bda0f5ab9296)
注意 是 与 的凸函数。因此,可以采用传统的梯度下降(或SGD)方法,其中不是在函数梯度的方向上前进,而是在从函数的次梯度中选出的向量的方向上前进。该方法的优点在于,对于某些实现,迭代次数不随着数据点的数量 而增加或减少。[13]

SVM的坐标下降算法基于对偶问题
对所有 进行迭代,使系数 的方向与 一致。然后,将所得的系数向量 投影到满足给定约束的最接近的系数向量。(通常使用欧氏距离。)然后重复该过程,直到获得接近最佳的系数向量。所得的算法在实践中运行非常快,尽管已经证明的性能保证很少。[14]


性质
SVM属于广义线性分类器的一族,并且可以解释为感知器的延伸。它们也可以被认为是吉洪诺夫正则化的特例。它们有一个特别的性质,就是可以同时最小化经验误差和最大化几何边缘区; 因此它们也被称为最大间隔分类器。
Meyer、Leisch和Hornik对SVM与其他分类器进行了比较。[15]
SVM的有效性取决于核函数、核参数和软间隔参数 C 的选择。 通常会选只有一个参数 的高斯核。C 和 的最佳组合通常通过在 C 和 为指数增长序列下网格搜索来选取,例如 ; 。通常情况下,使用交叉验证来检查参数选择的每一个组合,并选择具有最佳交叉验证精度的参数。或者,最近在贝叶斯优化中的工作可以用于选择C和γ,通常需要评估比网格搜索少得多的参数组合。或者,贝叶斯优化的最近进展可以用于选择 C 和 ,通常需要计算的参数组合比网格搜索少得多。然后,使用所选择的参数在整个训练集上训练用于测试和分类新数据的最终模型。[16]



SVM的潜在缺点包括以下方面:
- 需要对输入数据进行完全标记
- 未校准类成员概率
- SVM仅直接适用于两类任务。因此,必须应用将多类任务减少到几个二元问题的算法;请参阅多类SVM一节。
- 解出的模型的参数很难理解。
延伸
- 支持向量聚类:支持向量聚类是一种建立在核函数上的类似方法,同适用于非监督学习和数据挖掘。它被认为是数据科学中的一种基本方法。
- 转导支持向量机
- 多元分类支持向量机:SVM算法最初是为二值分类问题设计的,实现多分类的主要方法是将一个多分类问题转化为多个二分类问题。常见方法包括“一对多法”和“一对一法”,一对多法是将某个类别的样本归为一类,其他剩馀的样本归为另一类,这样k个类别的样本就构造出了k个二分类SVM;一对一法则是在任意两类样本之间设计一个SVM。
- 支持向量回归
- 结构化支持向量机:支持向量机可以被推广为结构化的支持向量机,推广后标签空间是结构化的并且可能具有无限的大小。
实现
最大间隔超平面的参数是通过求解优化得到的。有几种专门的算法可用于快速解决由SVM产生的QP问题,它们主要依靠启发式算法将问题分解成更小、更易于处理的子问题。
另一种方法是使用内点法,其使用类似牛顿法的迭代找到卡罗需-库恩-塔克条件下原型和对偶型的解。[17] 这种方法不是去解决一系列分解问题,而是直接完全解决该问题。为了避免求解核矩阵很大的线性系统,在核技巧中经常使用矩阵的低秩近似。
另一个常见的方法是普莱特的序列最小优化算法(SMO),它把问题分成了若干个可以解析求解的二维子问题,这样就可以避免使用数值优化算法和矩阵存储。[18]
线性支持向量机的特殊情况可以通过用于优化其类似问题逻辑斯谛回归的同类算法更高效求解;这类算法包括次梯度下降法(如PEGASOS[19])和坐标下降法(如LIBLINEAR[20])。LIBLINEAR有一些引人注目的训练时间上的特性。每次收敛迭代花费在读取训练数据上的时间是线性的,而且这些迭代还具有Q-线性收敛特性,使得算法非常快。
一般的核SVM也可以用次梯度下降法(P-packSVM[21])更快求解,在允许并行化时求解速度尤其快。
许多机器学习工具包都可以使用核SVM,有LIBSVM、MATLAB、SAS[22]、SVMlight、kernlab[23]、scikit-learn、Shogun、Weka、Shark[24]、JKernelMachines[25]、OpenCV等。
参见
参考文献
外部链接
Wikiwand - on
Seamless Wikipedia browsing. On steroids.